Spark相对于Hadoop来说一个最大的优势就是可以支持迭代运算在内存当中进行,正如Spark官网首页上列出的第一个优势“Speed”,官方是这样描述的:
Speed
Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk. Apache Spark has an advanced DAG
execution engine that support acyclic data flow and in-memory
computing.
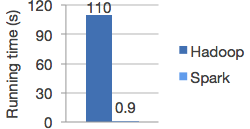
同时官方还给了这样一张图来说明对于迭代式计算的逻辑回归而言,Spark比Hadoop快了可不是一点半点。
对于in-memory的Spark来说,了解一下其内存管理还是十分重要的,因为Spark的in-memory的计算特性,其对内存的消耗还是很巨大的,如果对Spark的内存管理不够了解便不能充分利用所有的内存资源,并且很容易导致内存不够用时中间数据被缓存到了磁盘当中影响计算的速度。
Spark内存管理接口
Spark为存储内存和执行内存的管理提供了统一的抽象类——MemoryManager,同一个Executor内的任务都调用这个抽象类的方法来申请或释放内存,几个关键的内存管理接口定义如下:
1 | def acquireStorageMemory( |
Spark的内存系统随着Spark版本的发展具有非常多的变化,1.6.0版本之后新的内存管理模块的实现类为UnifiedMemoryManager,1.6.0版本之前采用的静态管理StaticMemoryManager方式仍被保留,称为Legacy模式。Legacy模式默认是关闭的,需要通过增加一个配置参数spark.memory.useLegacyMode=true来开启。
内存管理
静态内存管理
首先来简略地了解一下Spark 1.6.0版本之前的内存管理模型,对于一个Executor,内存一般由3个部分构成:
- Executor Memory,这片内存区域是为了解决shuffle、joins、sorts以及aggregations过程中为了避免繁琐的IO需要的buffer,可以通过参数
spark.shuffle.memoryFraction配置,其默认值为0.2。 - Storage Memory,这片内存区域是用于RDD的cache、persist以及broadcasts和task results的存储,可以通过参数
spark.storage.memoryFraction配置,默认值为0.6. - Other Memory,给系统预留的,因为程序本身运行也是需要内存的,其默认比例为0.2。
除此之外,为了防止OOM,一般都会有个safetyFraction,这种内存分配机制最大的问题就是其静态性,每个部分都不能超过自己的上限,规定了多少就是多少,这在Storage Memory和Executor Memory当中尤为严重。借用别人的一张图片能够很清楚的说明静态内存的分配方式:
统一内存管理
首先来看一张图片,这张图片很清晰地展示了1.6.0版本之后Spark在堆内存当中的使用情况。

从图片当中可以看到,在这种方式的内存管理下,一共有3个主要的内存区域,分别为Reserved Memory、User Memory和Spark Memory,接下来分别对这3块内存区域进行说明:
- Reserved Memory,这块内存区域是Spark系统预留的内存区域,用于存储Spark的内部对象,它的大小是在源码当中固定死的,为300MB,我们可以从源码中看到这段对Reserved Memory限定的代码:
1 | // Set aside a fixed amount of memory for non-storage, non-execution purposes. |
Reserved Memory的大小只能通过自己编译修改过的Spark源码来实现更改,还有一点需要说明的是,如果给每个Executor设定的内存值小于1.5 * Reserved Memory = 450MB,Executor将不会被正常启动,会报一个错误信息“please use larger heap size”。我们也可以从源码的注释信息中看到,用于execution和storage的内存大小为(Java Heap Memory - Reserved Memory) * 0.75,即Spark 1.6.0中spark.memory.fraction的默认值为0.75,但是目前版本的Spark,其默认值为0.6。
User Memory,这块内存区域为用户内存,用于用户保存在RDD转换操作中需要使用的自己的数据结构。这块区域的大小为
(Java Heap Memory - Reserved Memory) * (1 - spark.memory.fraction),对于这块区域的使用,Spark对于用户使用这块内存区域做什么以及使用的内存是否会超出这个区域的限制都不加管束,因此用户在使用时如果不加注意,很容易产生OOM的问题。Spark Memory,这块内存区域由Spark来管理和使用,其大小为
(Java Heap Memory - Reserved Memory) * spark.memory.fraction。这块内存区域又会被分为两部分,分别为Storage Memory和Execution Memory,这两块区域的大小通过一个参数spark.memory.storageFraction来控制,其默认值为0.5。Legacy内存管理方式下,对于这两块区域的限定有一个非常好的优点就是这两块区域内存大小的限定并不是静态的,根据两块内存区域的内存压力这个划分边界会随之改变,一片区域的内存大小会通过向另一片区域“借”内存来增加,一方空闲而另一方内存不足的时候,内存不足的一方可以借用另一方的内存。这种内存借用的机制会导致在内存“归还”的时候需要释放借用的那部分内存,对于Storage Memory占用了Executor Memory的情况,当Executor Memory不够用需要Storage Memory归还占用的内存的时候,这时会强制释放Storage Memory中属于Executor Memory的那部分内存,Storage Memory丢失的那部分数据会在下次使用的时候被重新计算;对于Executor Memory占用Storage Memory的情况,当Storage Memory内存不够用的时候,不会强制释放被Executor Memory占用的那部分属于Storage Memory的内存,Storage Memory会一直等待,直到Executor Memory主动释放其占用的那部分属于Storage Memory的内存,因为强制释放Executor Memory会导致任务失败。接下来再详细说一下Storage Memory和Executor Memory。
- Storage Memory
用来存储Spark缓存的数据(RDD的cache或者说是persist)、unroll数据以及广播变量。unroll指的是将序列化的数据反序列化为可以直接被访问的数据,Storage Memory中有一部分被称为Unroll Memory,在Spark中数据可以以序列化和反序列化的形式存储,序列化后的数据是无法直接被访问的,只有反序列化之后才可以被使用,反序列化过程中用到的内存就是Unroll Memory,Spark中大部分数据都是以序列化的方式进行传输的。 - Executor Memory
这部分内存用来存储Spark执行task过程中需要用到的对象,例如shuffle过程中mapper的输出,这部分的内存区域不够用时,也支持将数据写到磁盘上。Execution Memory当中有一部分为Shuffle Memory,是shuffle阶段使用的内存,主要用在sort上,如果这一块没有足够的内存来做shuffle,将会出现OOM。
参考文献
- http://www.leocook.org/2016/10/13/spark%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86/
- https://0x0fff.com/spark-memory-management/
- https://www.ibm.com/developerworks/cn/analytics/library/ba-cn-apache-spark-memory-management/index.html
- http://spark.apache.org/docs/1.6.0/configuration.html#memory-management
- https://zhuanlan.zhihu.com/p/26905029
- https://www.jianshu.com/p/b250797b452a